vue router 的命名视图
vue router 能够很好的解决页面跳转的问题。 但是以前的用法,我只会在组件里最多写一个 RouterV…

vue router 能够很好的解决页面跳转的问题。 但是以前的用法,我只会在组件里最多写一个 RouterV…
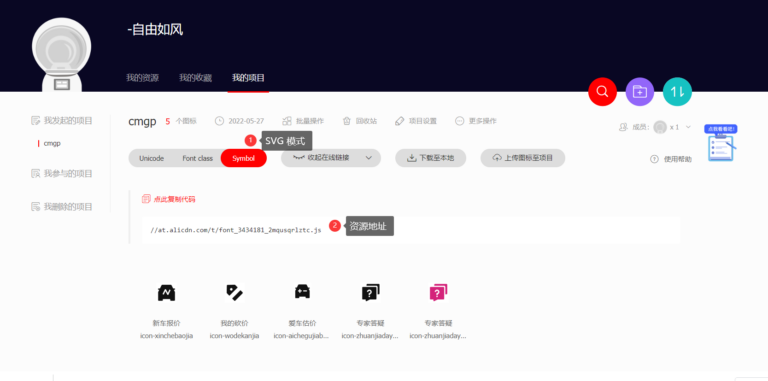
已知 iconfont 是非常好用的图标库,那么如何在项目里使用它呢? 创建 Iconfont 项目 将资源引…
官网地址 原文地址 unicode 引用 unicode是字体在网页端最原始的应用方式,特点是: 兼容性最好,…

如果你会使用 npm ,只需要这样的表格,则会使用 yarn NPM Yarn 说明 npm init yar…
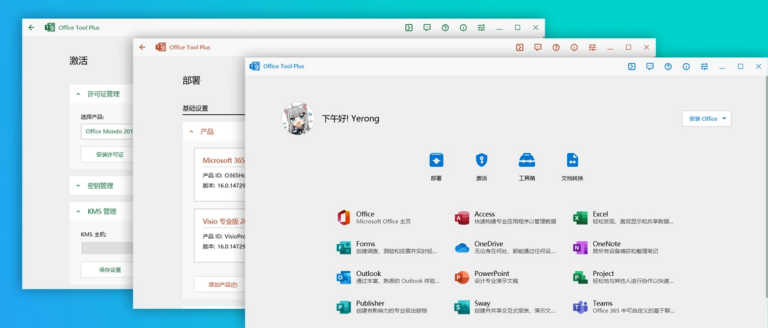
网上的激活方式五花八门,有一种通用的工具可以解决部署和激活的问题,上手加单。 官网 Office Tool P…


Redis 是完全开源免费的,遵守BSD协议,是一个高性能的key-value数据库。 在 windows 下…
IOC是Inversion of Control的缩写,多数书籍翻译成“控制反转”。 DI是依赖注入。 IOC…
过滤器(Filter)和拦截器(Interceptor)的区别 spring的拦截器和servlet的过滤器有…
Apache Shiro™是一个功能强大且易于使用的 Java 安全框架,它执行身份验证、授权、加密和会话管理…